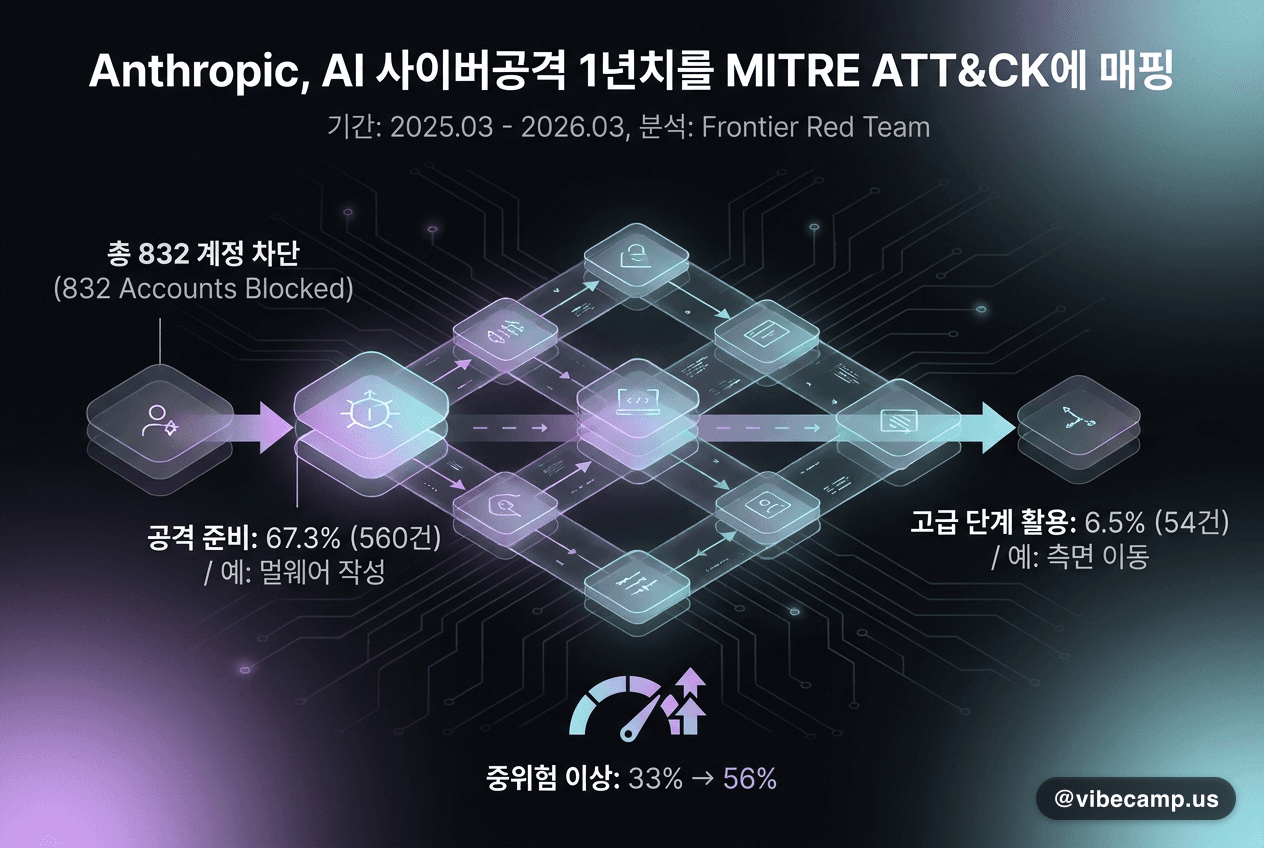
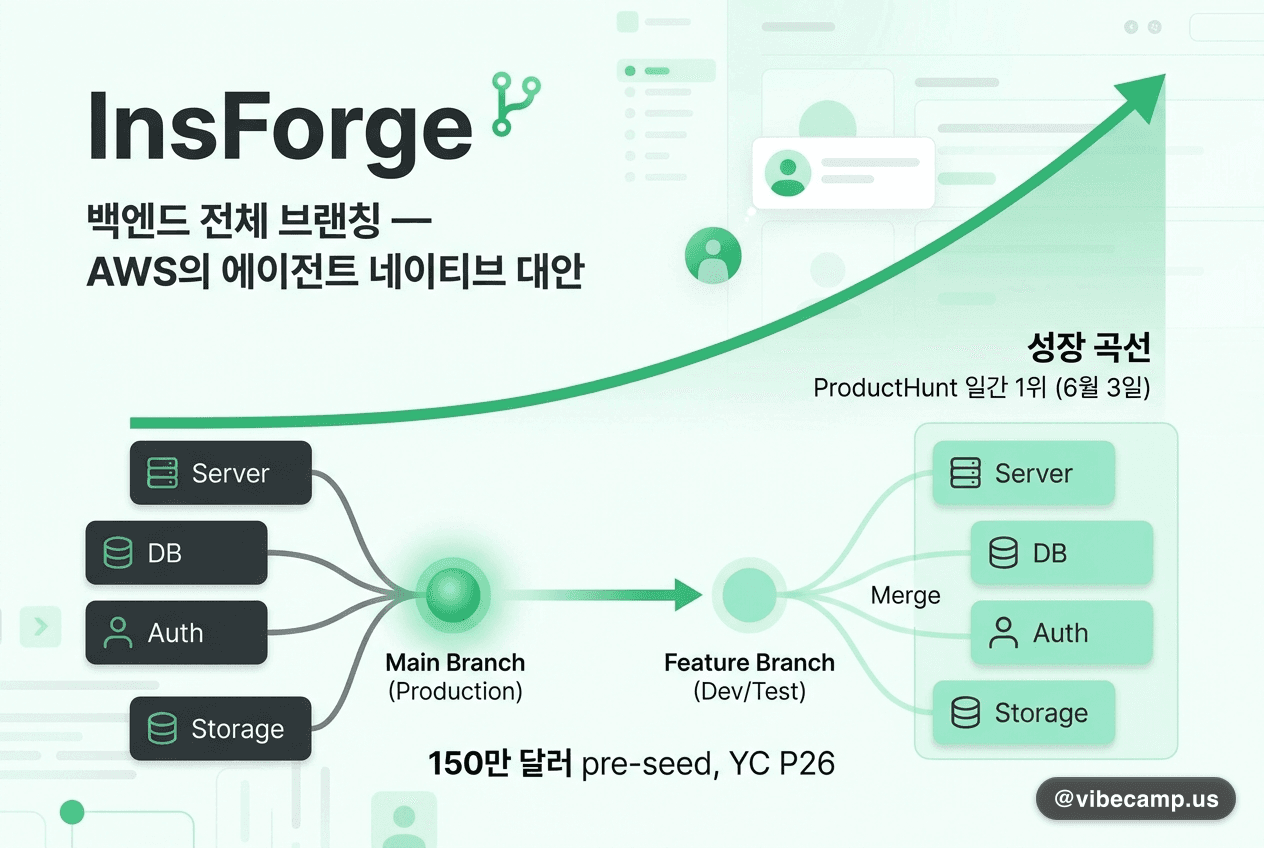
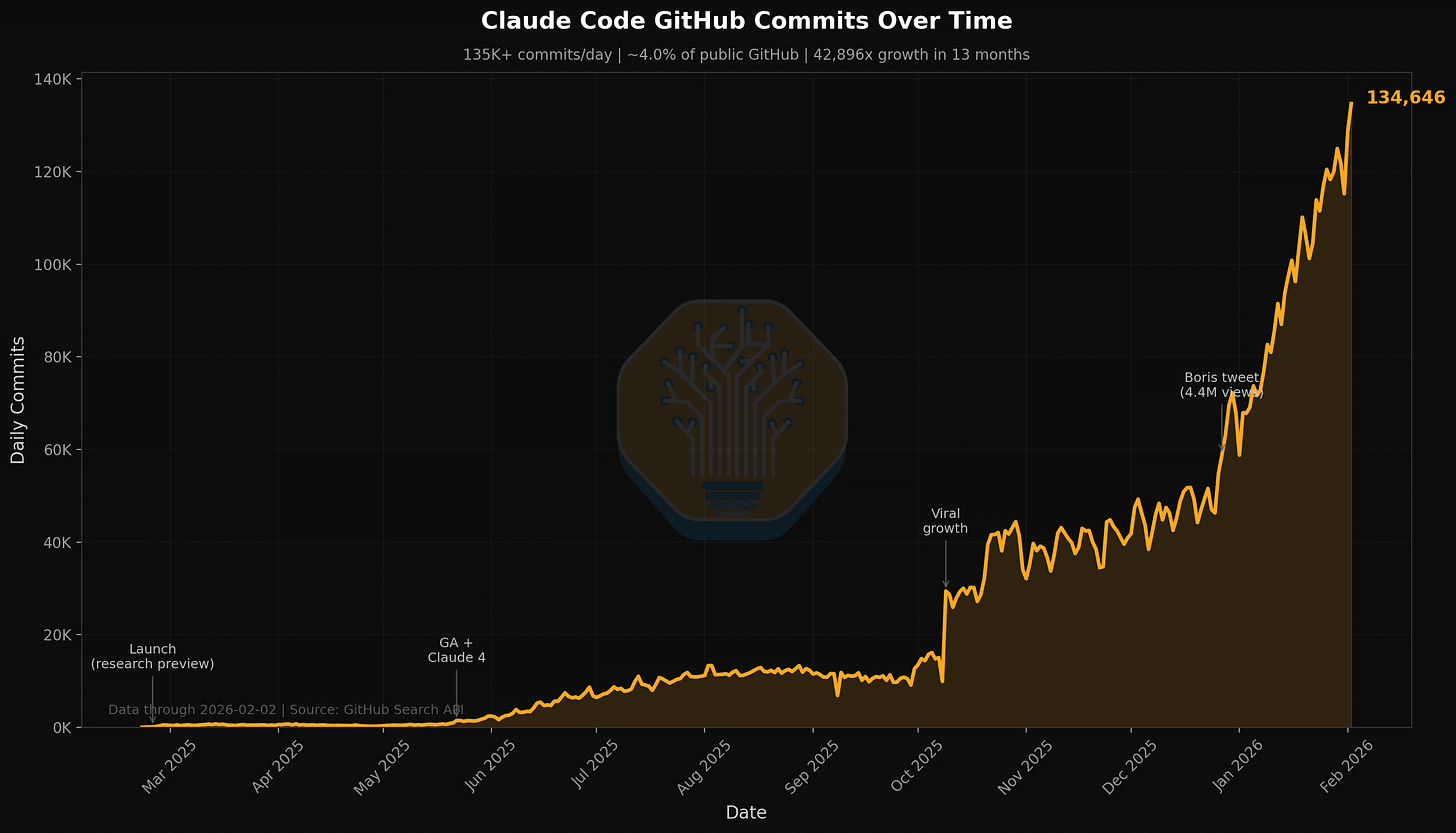
구글 Gemma 4 12B 공개 — 16GB 노트북에서 도는 멀티모달 오픈 모델
구글 딥마인드가 6월 3일 Gemma 4 12B를 Apache 2.0으로 공개했습니다. 멀티모달 인코더를 아예 없애고 이미지 패치와 오디오 파형을 가벼운 선형 레이어로 LLM 임베딩 공간에 직접 투영하는 새 아키텍처가 특징입니다. 16GB VRAM이나 통합 메모리에서 로컬 구동되고, 256K 토큰 컨텍스트와 140개 이상 언어를 지원하며, 음성 입력을 기본 탑재한 첫 중형 Gemma입니다.
💡API 토큰 비용 없이, 민감 데이터를 기기 안에 둔 채 멀티모달 에이전트를 노트북에서 직접 굴릴 수 있다는 뜻입니다.
- 누가
- Google DeepMind (Gemma team)
- 무엇을
- Gemma 4 12B — an open-weight, encoder-free multimodal model (native vision + audio) with a 256K context, runnable on 16GB VRAM, released under Apache 2.0
- 언제
- 2026-06-03T00:00:00Z
- 왜
- Separate multimodal encoders add latency and memory; folding vision/audio directly into the LLM backbone makes a capable multimodal model small and fast enough to run agentically on a laptop
#gemma#open-source#multimodal#local-llm