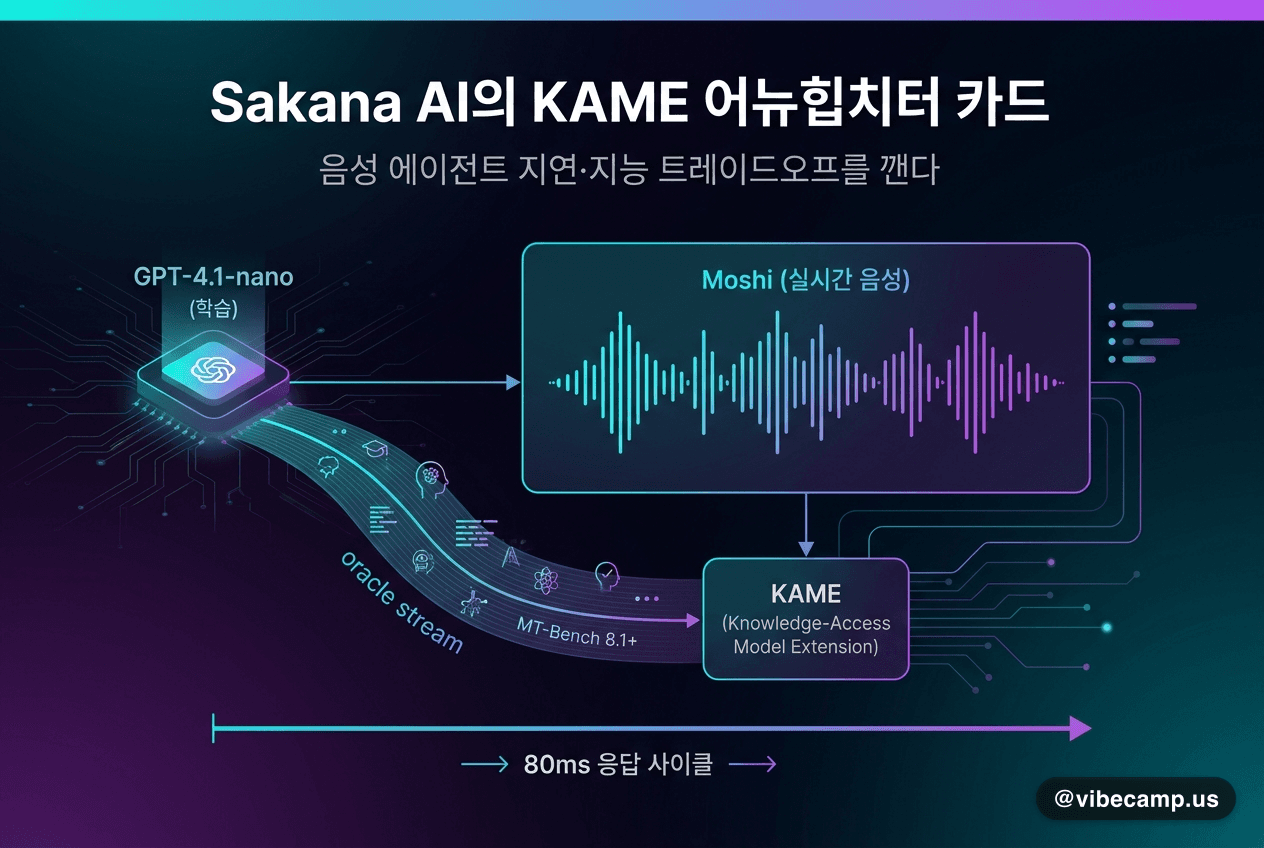
Sakana AI의 KAME, 음성 에이전트 지연·지능 트레이드오프를 깬다
Sakana AI가 5월 3일 공개한 KAME(Knowledge-Access Model Extension)는 Moshi 기반 실시간 음성 모델 앞단에 백엔드 LLM(GPT-4.1-nano로 학습)을 비동기로 붙이는 탠덤 구조입니다. 80ms 응답 사이클을 유지하면서 발화 도중 'oracle stream'으로 LLM 지식을 흘려넣어, MT-Bench 점수가 Moshi 2.05에서 KAME 6.43으로 3배 이상 뛰었습니다. 백엔드는 Claude Opus·Gemini로 교체 가능합니다.
💡음성 비서·라이브 튜터·통화 자동화를 만들 때 '추론은 LLM에 위임, 발화는 S2S로'라는 분리 패턴의 첫 공개 레퍼런스로 활용할 수 있습니다.
- 누가
- Sakana AI (Tokyo 기반 연구소, Llion Jones / David Ha 이끄는 팀)
- 무엇을
- Moshi 기반 front-end S2S와 back-end LLM(GPT-4.1-nano로 학습, Claude Opus·Gemini 등 plug-and-play)을 비동기 병렬로 묶고 'oracle stream'이 응답 중간에 조건을 주입하는 KAME 아키텍처 공개
- 언제
- 2026-05-03T12:00:00Z (marktechpost 게재일 기준; KAME 논문/모델 공개 자체도 동일 주차)
- 왜
- 음성 에이전트의 '빠르지만 얕다 vs. 똑똑하지만 2초+ 지연' 트레이드오프를 깨고, 80ms 사이클로 말하는 도중에 LLM 지식을 흘려넣어 두 마리 토끼를 잡기 위함
#voice-agent#speech-to-speech#sakana-ai#llm#low-latency
이미지: AI 생성 이미지원문 →