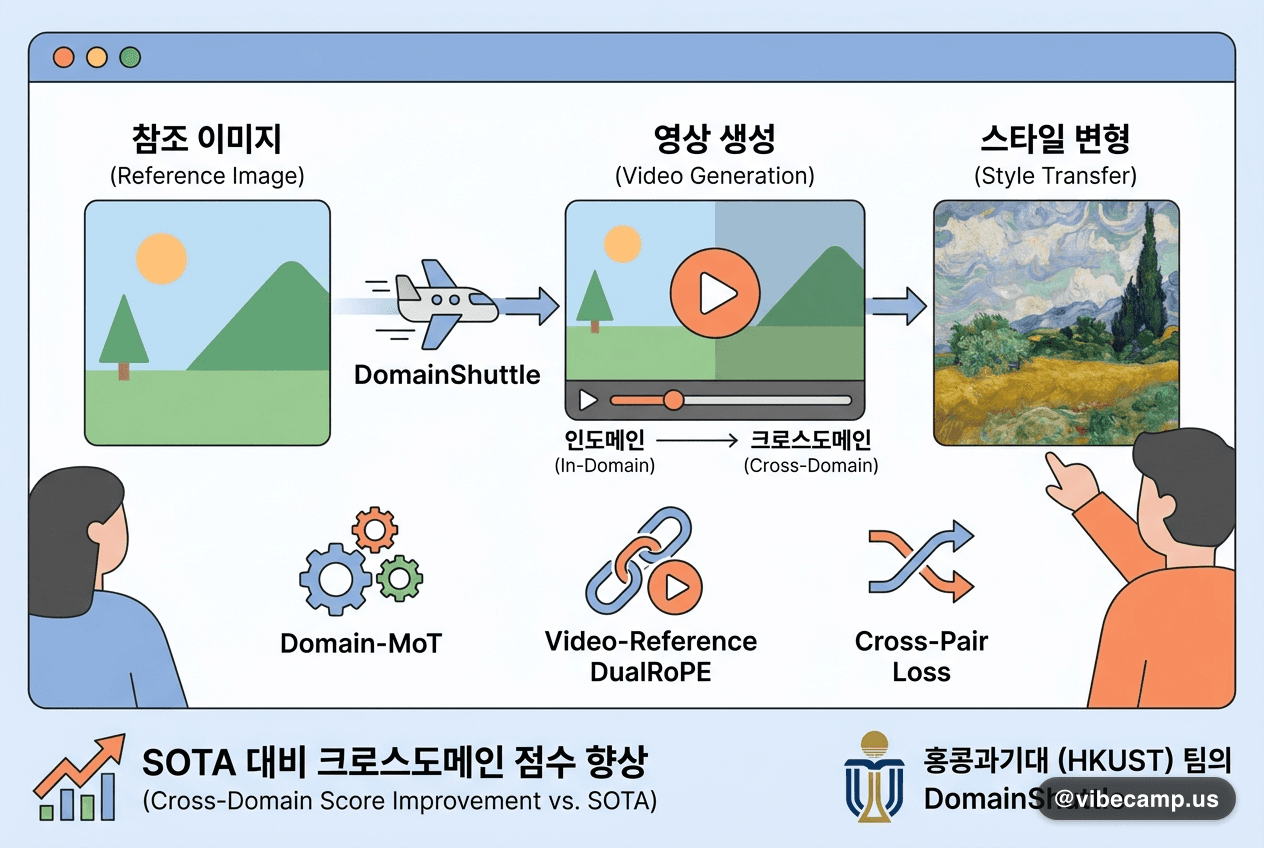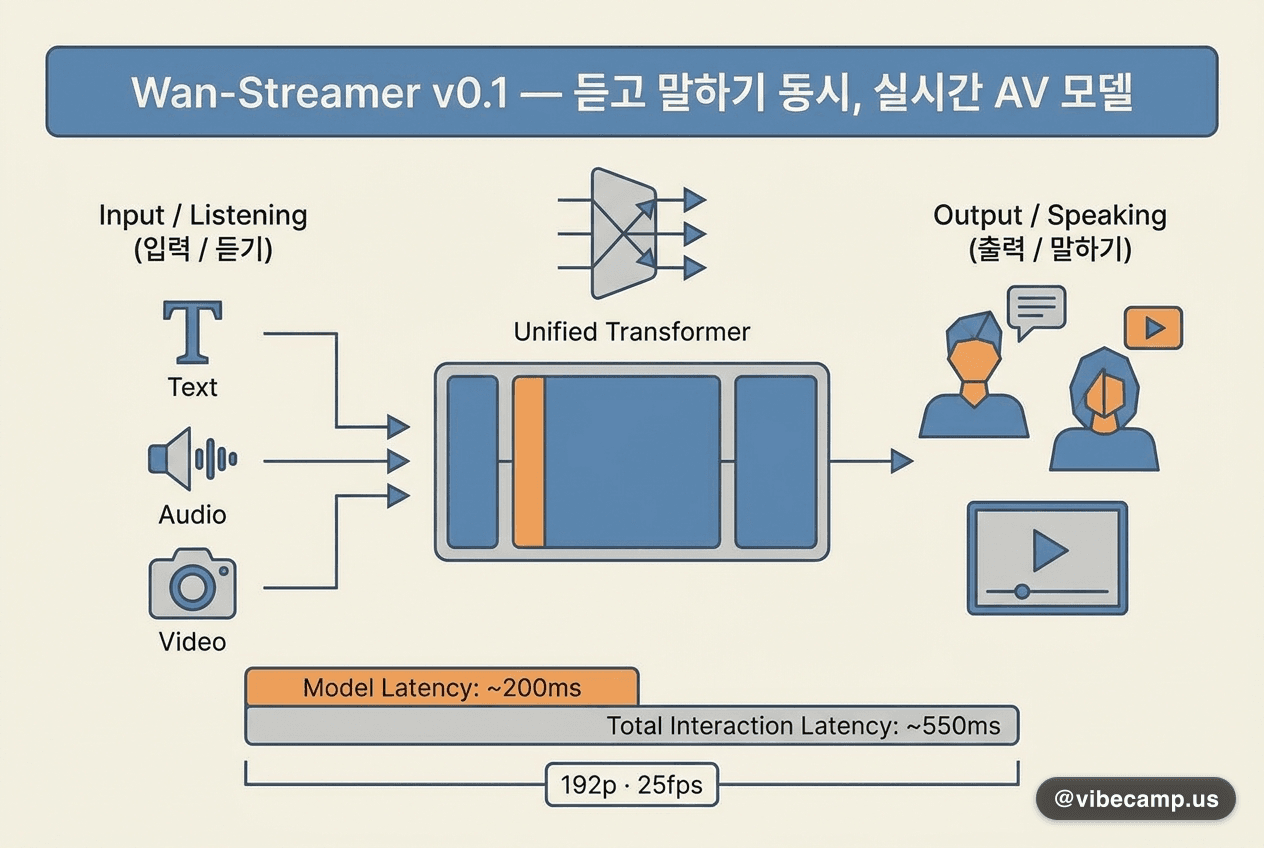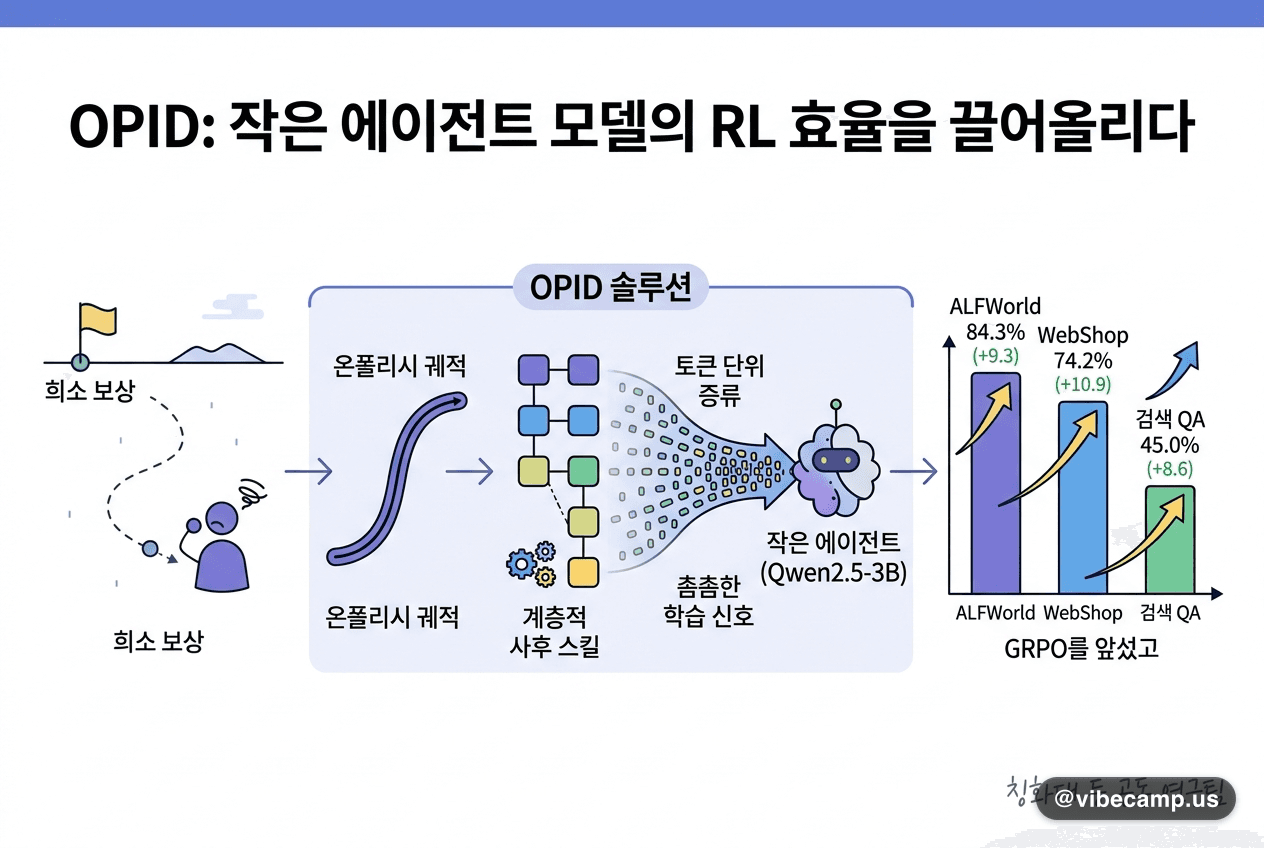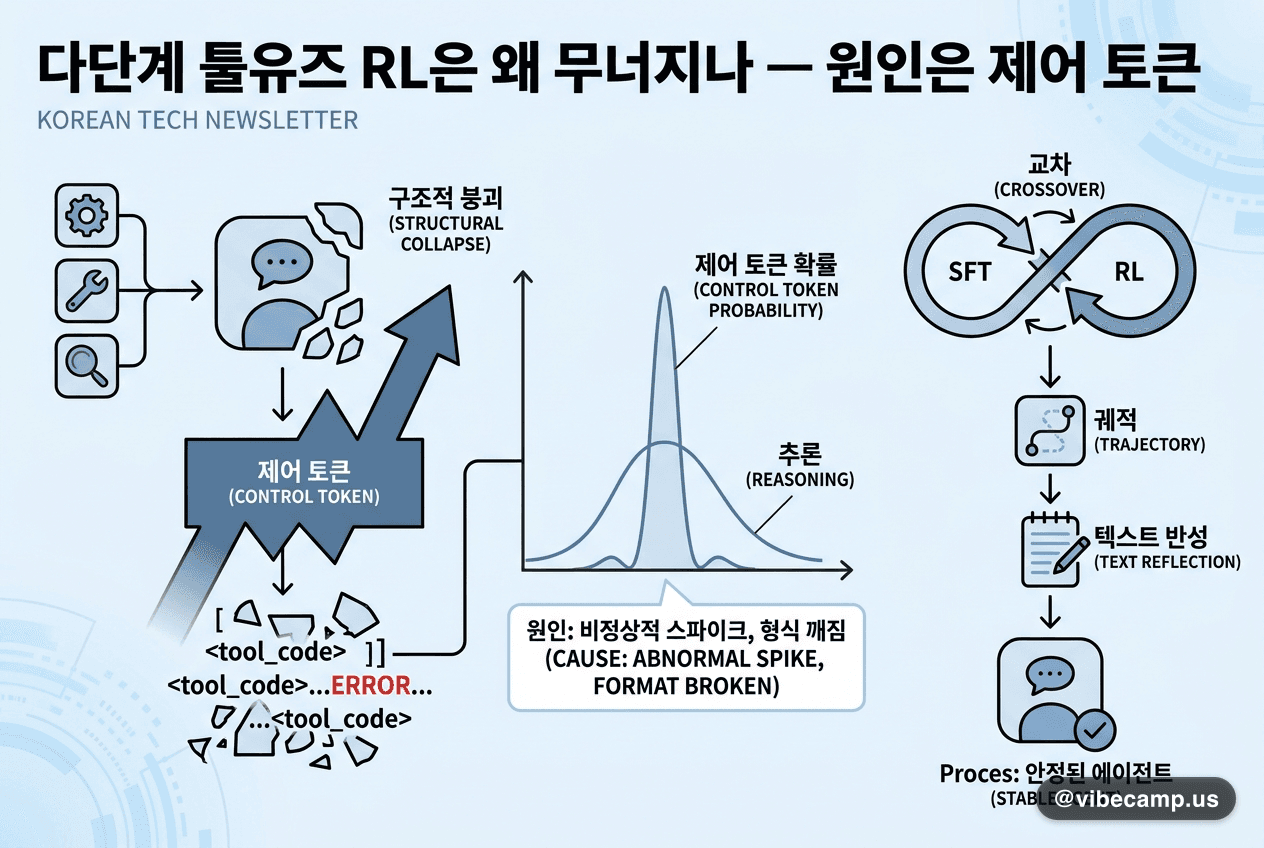
iLLaDA — 8B 확산 언어모델, Qwen2.5 7B와 경쟁
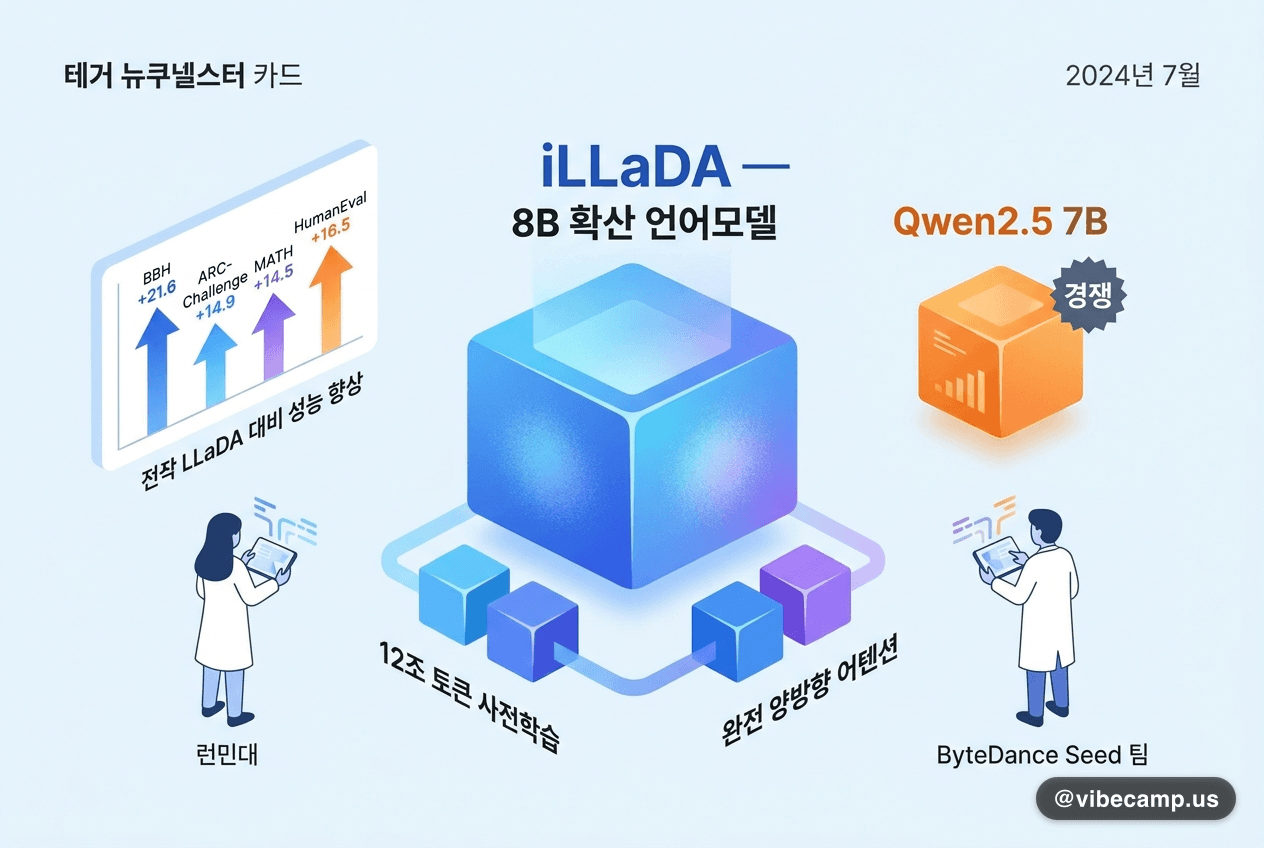
#런민대와 ByteDance Seed 팀이 80억 파라미터 마스크 확산(masked diffusion) 언어모델 iLLaDA를 공개했습니다. 완전 양방향 어텐션으로 12조 토큰을 사전학습했고, 전작 LLaDA 대비 BBH +21.6, ARC-Challenge +14.9, 명령어 튜닝본은 MATH +14.5·HumanEval +16.5만큼 올랐습니다. iLLaDA-Base는 MMLU·GSM8K 등에서 자기회귀(autoregressive) 모델인 Qwen2.5 7B와 경쟁하거나 앞섭니다.
💡확산형 LLM이 같은 체급 AR 모델과 붙을 수 있다는 신호로, 병렬 디코딩 같은 다른 추론 특성을 실험하려는 학습자에게 새 선택지가 됩니다.