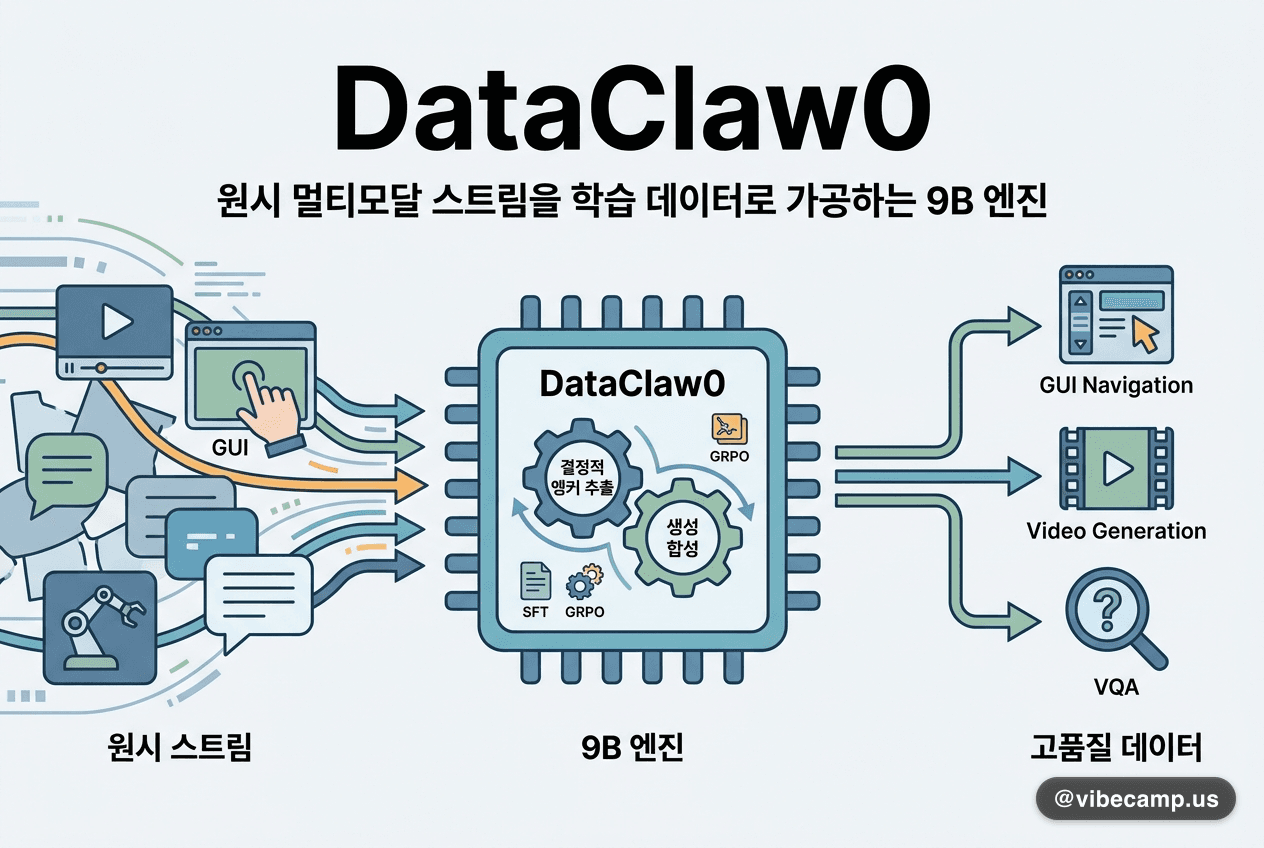
DataClaw0, 원시 멀티모달 스트림을 학습 데이터로 가공하는 9B 엔진
#DataClaw0는 비디오·GUI 조작·로봇 궤적·텍스트 같은 거친 멀티모달 스트림을 구조화된 고품질 학습 데이터로 바꾸는 에이전트형 모델입니다. 결정적 앵커 추출과 생성 합성을 결합했고, Qwen3.5 기반 9B를 SFT와 GRPO로 학습했습니다. 34K 정제 예제·8×A100으로 학습해 GUI 내비게이션·비디오 생성·VQA 과제에서 상용 어노테이터와 동급 이상 결과를 냈습니다.
💡상용 어노테이션에 돈을 쓰는 대신 오픈 모델로 멀티모달 학습셋을 자동 정제하는 레시피라, 데이터 파이프라인을 직접 굴리는 1인 개발자에게 실용적입니다.