Liquid AI, 한국어 포함 11개 언어 350M 임베딩 모델 공개
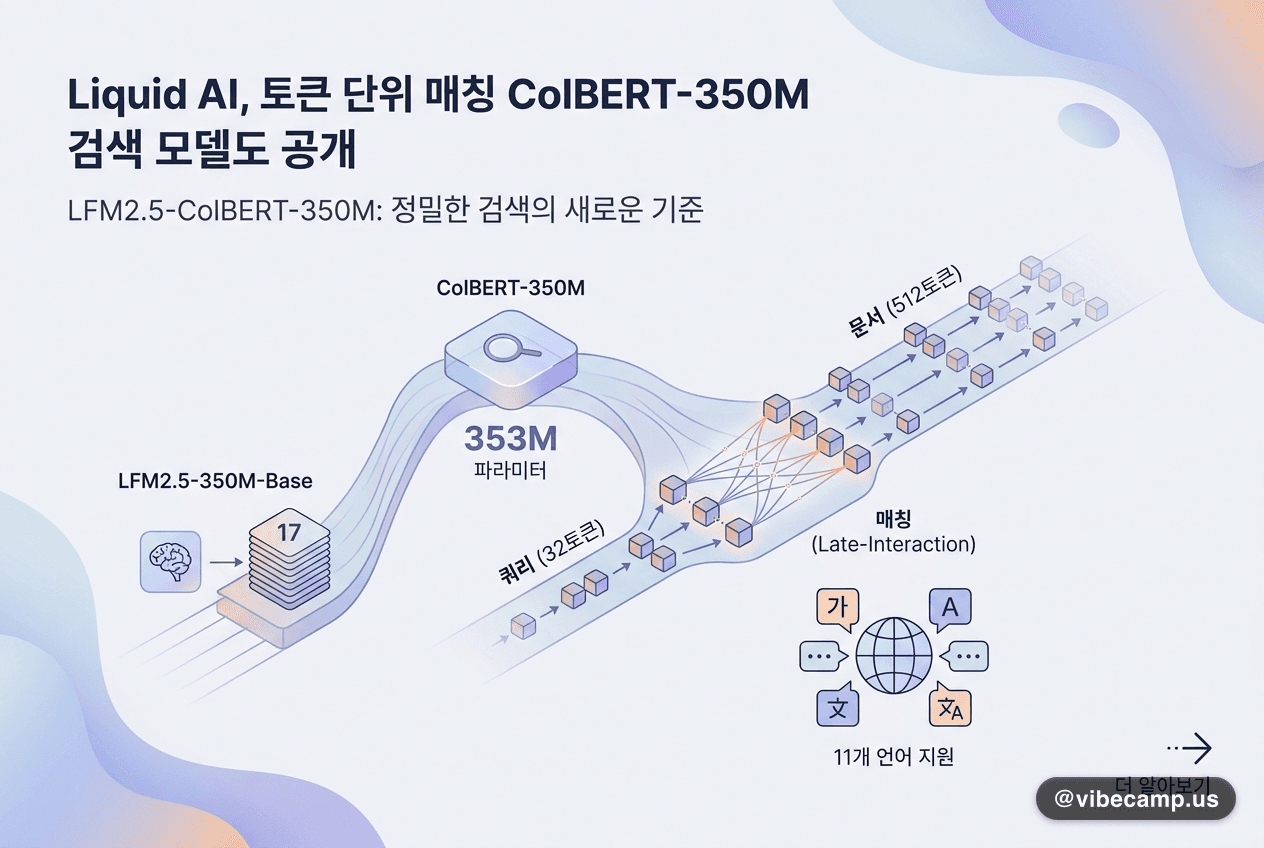
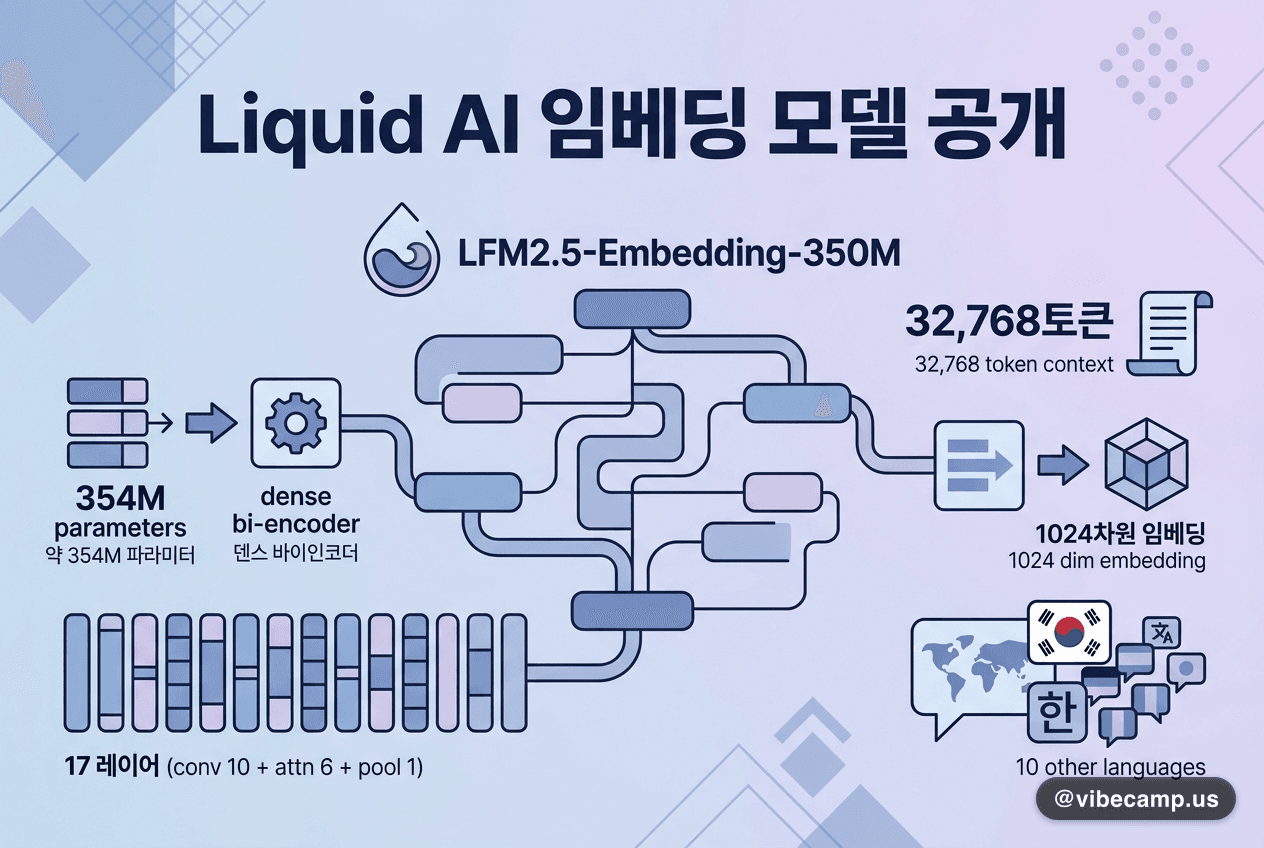
#Liquid AI가 약 354M 파라미터의 덴스 바이인코더(dense bi-encoder) LFM2.5-Embedding-350M을 공개했습니다. LFM 계열 최초로 인과 디코더를 양방향 인코더로 전환한 17레이어(conv 10 + attn 6 + pool 1) 구조이며, 컨텍스트 32,768토큰·1024차원 임베딩을 지원합니다. 한국어를 포함한 11개 언어에서 NanoBEIR ML NDCG@10 0.577, MKQA-11 Recall@20 0.691을 기록하고, 엔터프라이즈 스택 기준 검색 지연 1.5ms 수준입니다.
💡프런티어 LLM을 검색 단계에 쓰는 대신, 350M 소형 임베딩으로 온디바이스·엣지 RAG의 비용과 지연을 낮추려는 팀에 곧바로 끼울 수 있는 다국어 옵션입니다.