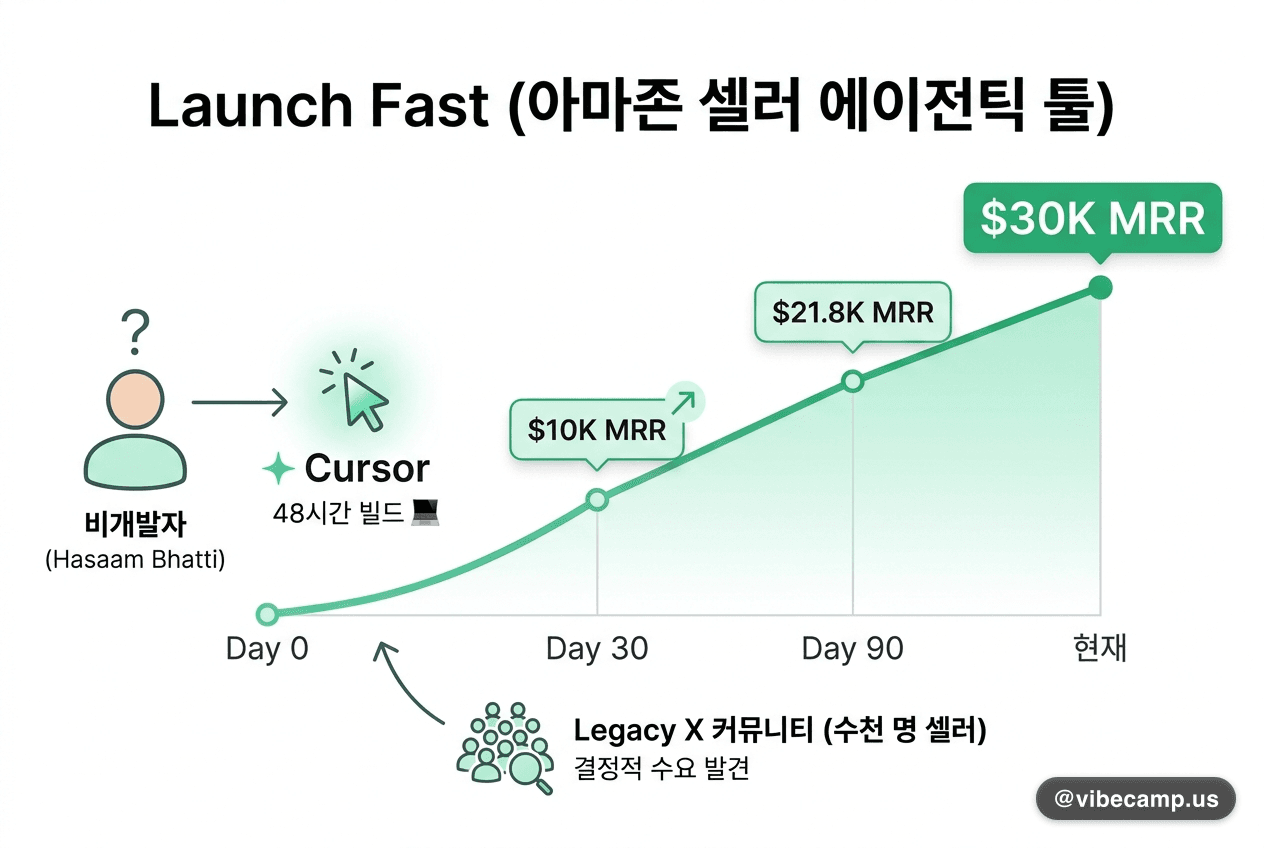
구글, 폰에서 1GB 미만으로 도는 Gemma 4 QAT 체크포인트 공개
#구글 딥마인드가 6월 5일 Gemma 4의 양자화 인식 훈련(QAT) 체크포인트를 공개했습니다. 완성된 모델을 압축하는 대신 훈련 중에 양자화를 시뮬레이션해, 후처리 양자화에서 흔히 생기는 품질 손실을 줄입니다. E2B 텍스트 모델은 용량이 1GB 미만으로 떨어져 폰·노트북에서 로컬로 돌아가고, llama.cpp·MLX·Ollama에서 바로 실행됩니다. Hugging Face와 Kaggle에 공개되어 있습니다.
💡오픈 멀티모달 모델을 클라우드 없이 기기에서 돌릴 수 있다는 뜻입니다. API 비용 0, 데이터 외부 유출 0인 온디바이스 추론(on-device inference)을 다음 프로젝트에 바로 시험해볼 수 있습니다.
Google ships Gemma 4 QAT checkpoints — open multimodal models that run under 1GB →#gemma#quantization#on-device#open-source#google